Parallel computing along with the concept of multithreading are two terms that most of the developers are afraid of and associate them with a huge amount of data races and hours and hours of debugging. However, every developer is faced with these issues at least once in their lifetime, and as with all things in life, it’s better to face the issue as soon as possible.
Having above said in mind, I will try to demystify some of the pitfalls of multithreading as well as show some interesting approaches.
So, let’s start with one of the most common cases…
Processing data in a separate thread
Let’s imagine a common situation where there is a continuous data flow that needs to be processed. Since we don’t want to occupy the main thread’s resources, the practical approach would be to separate processing into another thread.
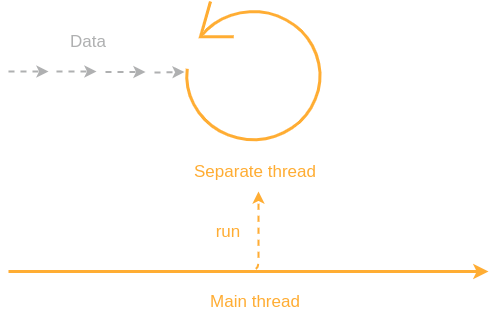
Now, how could we implement continuous processing in a separate thread’s body?
The very first thing that could come to some readers’ minds might be something like:
1
2
3
while (true) {
// process some data
}
Indeed, this approach would work but it’s not so pretty as it does not really allow us to fully control the processing. If we would ever want to stop the thread from working, we would need to brutally kill it or meet a condition (that might not even exist) that would break out of the loop.
So, don’t use this approach in your code… ⛔
But, it’s not the end of the world as there is a very well known way on how to solve this challenge in a bit more sophisticated manner…
You shall not… process anymore!
Let’s improve the naive solution from the previous section…
First, we need to add the ability to control the separate thread’s behavior from the main thread. This is achievable by using simple std::atomic<bool> (or similar std::atomic_flag) variable that can be set to true or false from the parent thread. This small change already greatly improves code expressiveness and thread handling.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <chrono>
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> is_stopped{ false };
void run() {
while (!is_stopped) {
std::this_thread::sleep_for(std::chrono::seconds{ 1 });
std::cout << "work" << std::endl;
}
}
int main() {
std::thread t(run);
std::this_thread::sleep_for(std::chrono::seconds{ 5 });
is_stopped = true;
t.join();
}
Play with the code on wandbox.
More power to the threads
Apart from the classical approach being shown in the previous section, thread’s behavior can be controlled in a bit more innovative way… by taking advantage of std::promises and std::futures. And… I must admit… the above example is pretty simple and, in this cruel world, source code gets more and more complex on a daily basis. Therefore, a bit more expressive solution would be preferable…
What do you think of creating a separate class which would be a base class for all our future non-blocking tasks? That would, eventually, emphasize the business logic and hide that ugly part of the thread handling.
Let’s take a look at the implementation of such a base class that I have called Thread (sounds so complicated… 😉):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class Thread {
public:
Thread() = default;
Thread(Thread const& other) = delete;
Thread(Thread&& other) = default;
Thread& operator=(Thread const& other) = delete;
Thread& operator=(Thread&& other) = default;
~Thread() {
join();
}
void start() {
if (!thread_.joinable()) {
stop_request_ = std::promise<void>();
thread_ = std::thread(
&Thread::run, this,
std::move(stop_request_.get_future())
);
}
}
void stop() {
try {
stop_request_.set_value();
} catch (std::future_error const& ex) {
// ignore exception in case of multiple calls to 'stop' function
}
}
void join() {
if (thread_.joinable()) {
thread_.join();
}
}
protected:
virtual void run(std::future<void> const& stop_token) = 0;
static bool is_stop_requested(std::future<void> const& token) noexcept {
if (token.valid()) {
auto status = token.wait_for(std::chrono::milliseconds{ 0 });
if (std::future_status::timeout != status) {
return true;
}
}
return false;
}
private:
std::thread thread_;
std::promise<void> stop_request_;
};
First, start function is responsible for creating an instance of std::promise<void> and running the separate thread that owns std::future<void> associated with std::promise. Now, if we ever decide to move the instance of our Thread class, we will be able to stop its execution.
With above being said, stop_request_ data member is a some sort of a signal, i.e. once the stop function is being called and the value of stop_request_ is set, stop_token will be ready and, thus, is_stop_requested function will return true. On the other hand, if we don’t call the stop function, the value of stop_request_ data member won’t be set and, therefore, stop_request_result_ won’t be ready.
Furthermore, notice the try...catch block inside the stop function. First call to stop function will store the value into the shared state but every following call will result in std::future_error exception because the shared state is already storing the value. That’s why we need to protect the end-user against this behavior.
At the end, there is a run function, a pure virtual function, which needs to be implemented in each class derived from the Thread class. This function is representing the actual work which will eventually get executed in a separate thread.
Now, let’s take a look at the example of a task that should use our new Thread class:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Task : public Thread {
public:
Task() = default;
Task(Task const& other) = default;
Task(Task&& other) = default;
Task& operator=(Task const& other) = default;
Task& operator=(Task&& other) = default;
~Task() = default;
private:
void run(std::future<void> const& stop_token) override {
std::cout << "Task start" << std::endl;
while (!is_stop_requested(stop_token)) {
std::cout << "Task body" << std::endl;
// simulate processing
std::this_thread::sleep_for(std::chrono::seconds{ 2 });
}
std::cout << "Task end" << std::endl;
}
};
As you might have already noticed, Thread base class has brought some expressiveness and cleanliness to the source code giving the reader ability to put the focus on the logic and not on the details related to the thread handling. is_stop_requested function is used for controlling the processing of the data in an elegant way, as opposed to the first example in this article. And now… let’s see how we can use the class above:
1
2
3
4
5
6
7
8
9
10
11
int main() {
Task task;
task.start(); // task processes some data
std::this_thread::sleep_for(std::chrono::seconds{ 10 });
task.stop(); // stop the processing after 10 seconds
return 0;
}
If you wish to experiment a bit, play with the code on wandbox.
What does C++20 bring?
All the code we have written above (which btw works with C++11) is great and it might work eventually, but developers tend to use standard stuff as much as they can (even though some of them always try to be smart and reinvent the wheel 🧐). They don’t want to bother themselves writing helper classes, utility functions etc. That’s where C++20 standard kicks in…
The most recent version of the C++ standard has introduced a component called: std::jthread.
std::jthread class has inherited the same general behavior from the std::thread class but it is extended with 2 additional features:
- automatically rejoining on destruction, and
- cancellation / stopping
Let’s see how we can use it…
The straightforward example of std::jthread’s usage would be something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <chrono>
#include <thread>
#include <iostream>
void run(std::stop_token st) {
while (!st.stop_requested()) {
std::cout << "Task body" << std::endl;
// simulate processing
std::this_thread::sleep_for(std::chrono::seconds{ 2 });
}
}
int main() {
std::jthread jt{ run };
std::this_thread::sleep_for(std::chrono::seconds{ 10 });
jt.request_stop();
std::cout << "Stop requested" << std::endl;
return 0;
}
Check out the live demo on wandbox.
As you might see, std::jthread’s constructor accepts a callable object to execute in the new thread. That callable object can (but does not have to) accept a std::stop_token as its first argument. std::stop_token is, at least by functionality, similar to our combination of stop_request_ data member and stop_token parameter of run function. It provides the means to check if a stop request has been made and can be made. So, eventually our is_stop_requested function has now been replaced by std::stop_token::stop_requested function.
Furthermore, if we want to send the stop signal from the parent thread, we can call std::jthread::request_stop function which is similar to our custom Thread::stop function.
At the end, some of the readers may say: Hey, we haven’t joined the thread! std::terminate will get called and the program will crash! But, as you might remember from the beginning of this section, std::jthread does not have to be joined explicitly. Its destructor is implemented as:
1
2
3
4
5
6
jthread::~jthread() {
if (joinable()) {
request_stop();
join();
}
}
So… with C++20, we have an easy way to stop the thread. But, what about pausing/resuming the thread? Do we need to implement it on our own? Would it be handy to have std::pause_token too? I leave answering these questions to you…
Conclusion
In this article, I have tried to explain a few things that can be achieved with C++11’s std::thread and its younger brother - C++20’s std::jthread. Our custom Thread class with functionalities explained above can also be implemented by using std::condition_variables and std::atomics. Do you like my approach? What’s the solution you prefer?
Let me know in the comments below… ⬇️👇